前端SEO优化总结
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
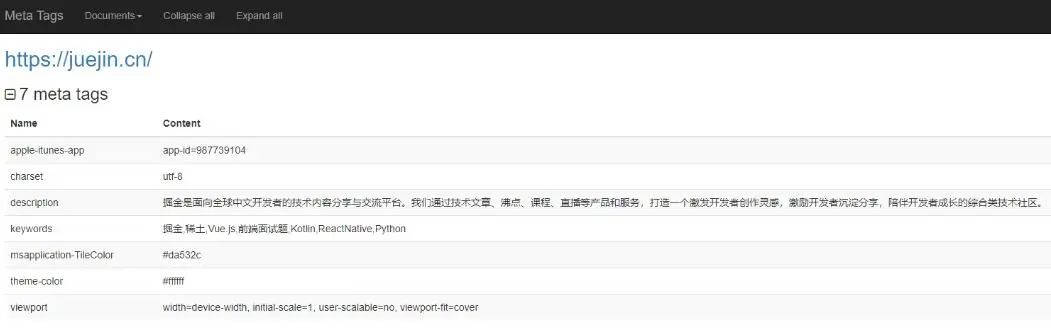
 来源 | https://juejin.cn/post/7300118821532778511 前言以前开发独立站,涉及过一些seo的内容,为了避免后面会遗忘,感觉有必要记录下相关经验,也算是一次总结吧! SEO概念SEO 是 Search Engine Optimizatio(搜索引擎优化) 的首字母缩写,利用搜索引擎的规则对网站进行内部及外部的调整优化,提高网页或网站在搜索引擎中关键词的自然排名, 以求得获得更多的展现量和吸引免费的点击流量,从而达到互联网营销及品牌建设的目标。 SEO的方式1. Title标签对页面点击率有直接影响,因为这是用户对网站页面的第一印象,而且也是爬虫重点的爬取对象,填写的文字要对网页内容有准确而简洁的描述,能够吸引用户点击,而且长度要适中。 2. Meta标签meta标签共有两个属性,分别是http-equiv属性和name属性,不同的属性又有不同的参数值,另外还有主要作用于社交平台的OG标签。 (1) name属性
(1) Google 在2009年正式宣布,keyword标签不再是排名的一部分。 (2) 在百度站长论坛上官方曾表示这个标签目前对SEO的影响可以忽略不计。
(2)http-equiv属性
(3) OG标签它是 Facebook 在 2010 年 F8 开发者大会公布的一种网页元信息(Meta Information)标记协议,属于 Meta Tag (Meta 标签)的范畴,是一种为社交分享而生的 Meta 标签。 为了让信息内容加速流动和准确呈现,Facebook 早年极力推动这个协议,到目前几乎主流的社交媒体网站都支持 OG 协议。包括 Twitter、Pinterest、LinkedIn 和 Google+ 都可以识别 OG 协议。 虽然 Twitter 也有自家的 Twitter Cards 协议,但是 Twitter 只要发现网页上没有使用自家的协议,就会用 OG 协议代替。国内的百度、360 搜索、微博、微信、人人网等也支持该协议。
OG在社交媒体上具有丰富的内容展示,比如分享一个网址链接在社交平台后,这个链接会显示缩略图、标题和描述等,增加访客点进来的概率。 标签详细属性可以看官网:ogp.me/ 3. 语义化标签H系列标签从H1到H6(重要性从高到低)一共有6个,而且在页面中的作用性极高,所以不能乱用,得根据内容的重要性进行排列,最后不要有断层,比如从H1直接到H3,错过了H2;另外,H1标签最好只存在一个,更多细节可以网上搜下。 img标签img的alt属性,为搜索引擎提供替代文本,图片使用alt标签优化,对搜索引擎排名产生积极影响;另外,网速不佳等原因造成无法加载图片文件时,将在图片的位置显示alt里的文字 其他还有HTML5新出的 Header, Nav,Aside,Article,Footer等语义化标签,这些都能帮助爬虫更好的获取页面内容 4. sitemap(站点地图)站点地图一般是xml格式的文件,放在网站的根目录下,有些网站甚至可以通过 网址/sitemap.xml 直接访问到(手动狗头),文件里包含了每个网页的链接(loc),更新时间(lastmod),权重(priority)等信息,权重从0到1,依次递增,一般主页设为1,然后其他按重要性递减。 搜索引擎可以通过查看站点地图快速获取网站的整体结构,并将精力集中在重要页面的索引上,这对于提高搜索引擎的爬行效率和索引速度非常有帮助。 5. robots文件robots.txt,是一个给爬虫下指令的文本文件,能让其合理地抓取网站内资源,而且可以将网站不重要的内容、模块等进行屏蔽,从而抓取更多有价值高质量的内容和网页,提高网站排名。大多数网站都可以通过网址/robots.txt进行获取。
6. 内链和外链内链在自己的网站当中通过链接的方式在各个内容页面之间相互链接,从而提高爬虫以及一些搜索引擎对于网站的爬行索引效率;另外,为了避免内链起到反作用,在进行网站待更新的时候,一定要注意定期清理死链和断链,方便爬虫可以顺着链接进行收录爬行,达到更好的收录效果。 外链通过在其他一些高流量的网站放置自己的链接,相较于内链的内部操作,外链可以达到网络之间的信息分享,不再让我们的网站内容形成孤立,可以很快的增加网站的浏览数量,提升搜索排名,这对一个刚刚建立起来的新站来说,外链的数量基本上可以成为这个网站快速提升流量的关键所在,不过对于后期优化,外链的发布一定要以质量为主,数量为辅。 nofollow
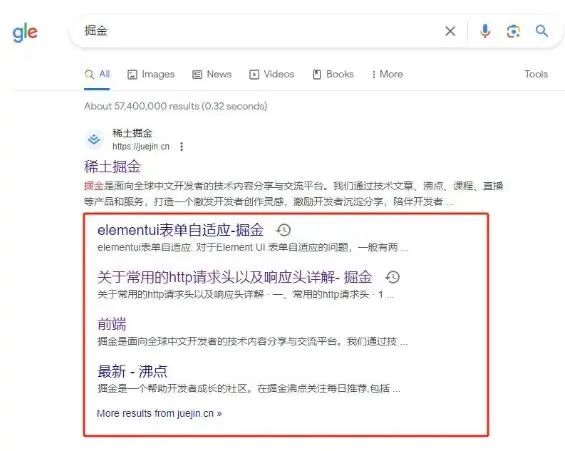
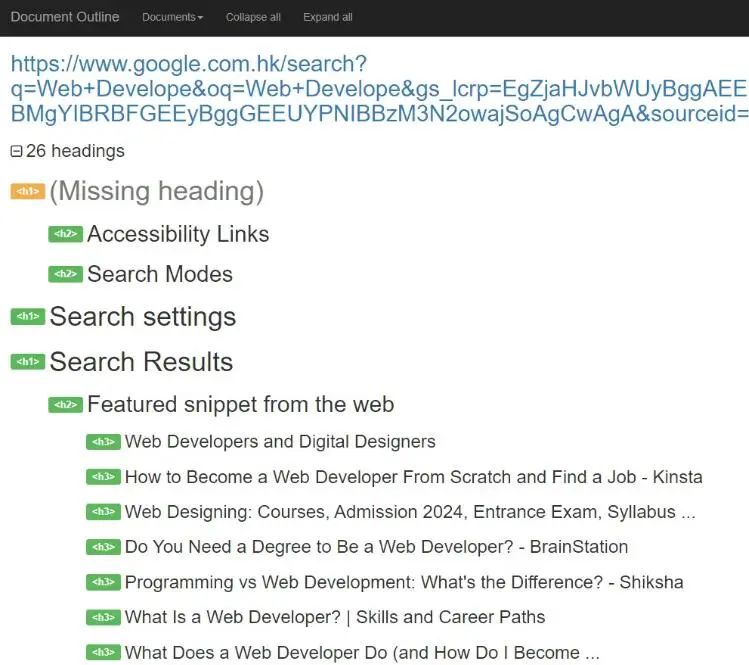
7.数据结构化标记结构化数据标记并不能直接帮助提高搜索排名,但它能带来很多好处: (1)丰富搜索结果比如搜索 掘金 出现的页面,红色框部分就是结构化标记的成果,从框内可以更好的了解该网站的内容,而且占据了大版面也有利于吸引用户注意。
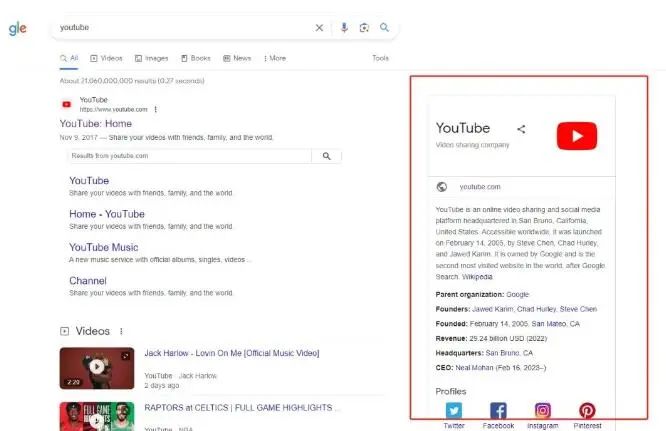
(2)拥有知识面板在右侧会有个知识面板,该面版可提供更高的品牌知名度和权威性,如下图的右侧红框:
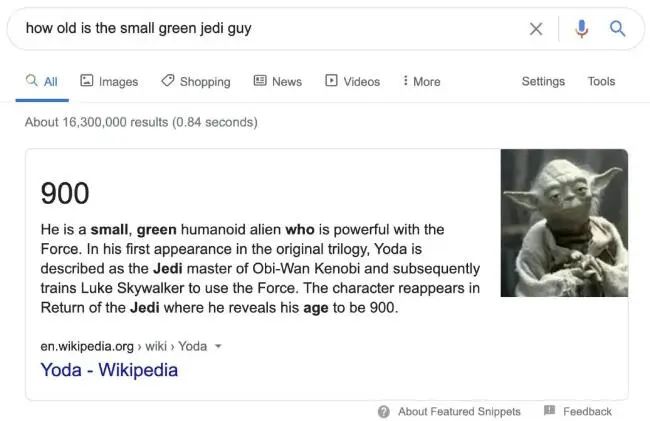
(3)支持语义搜索不再是关键词的匹配搜索,而是通过关键词去寻找问题的答案。当你搜索如下模糊内容时,Google 会通过这种方式设法返回合适的结果:
(4)体现 E-A‑TE‑A-T 意思 是专业(Expertise), 权威(Authoritativeness)和可信(Trustworthiness)的缩写, E-A-T是谷歌算法的一部分,并被写入谷歌搜索质量评估指南中。 结构化数据形式结构化数据有三种形式:JSON-LD,Microdata和RDFa。个人之前一直用的JSON-LD,如下:
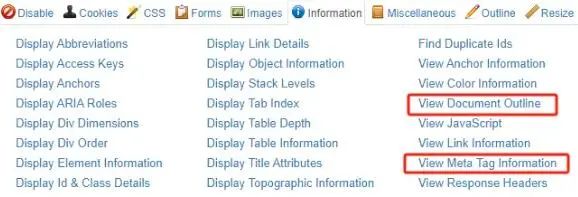
Tips这段代码可以放在<head> 或 <body> HTML 部分的任意位置,更多的JSON-LD款式可以参考 Google官方。 8.面包屑导航
9.服务端渲染(SSR)爬虫只会爬取源码,不会执行网站的Js脚本,使用了vue或者react之类的框架后,页面大多数dom元素都是在客户端根据js动态生成,可供爬虫抓取分析的内容大大减少。 另外,浏览器爬虫不会等待我们的数据完成之后再去抓取我们的页面数据。服务端渲染返回给客户端的是已经获取了异步数据并执行Js脚本的最终HTML,网络爬中就可以抓取到完整页面的信息,所以就要用到SSR渲染了。 如果是项目开始的时候,就知道要做SEO,建议使用比较成熟的SSR框架
如果是项目已经成形或者只想优化部分页面,建议使用一些插件来实现,比如 prerender-spa-plugin、vue-server-renderer ( 适用于Vue ) Tips: 爬虫不会抓取iFrame里的内容,所以尽量避免使用 10.网站地址
解决方案:可通过在每个非规范版本的 HTML 网页的 <head> 部分中,添加一个 rel="canonical" 链接来进行指定规范网址。
11.网站性能网站打开速度越快,识别效果越好,否则爬虫会认为该网站对用户不友好,降低爬取效率,这时候就要考虑压缩文件体积之类的性能优化了。 12. 使用httpsGoogle和其他搜索引擎已经明确表示,他们更喜欢使用HTTPS,因为它提供更高的安全性和更好的用户体验。当您的网站使用HTTPS时,搜索引擎会将其视为更可信和更安全的网站,从而为其排名增加积极因素。 13.提交站点收录将创建好的网站地图提交给搜索引擎,以便搜索引擎能够更快更及时地抓取和索引网站。
网站访问数据后期维护需要一定的网站访问数据做分析,比如流量来源,页面点击,地域分布等,不同的搜索引擎都有自己的一套分析工具,我们只要按照官网的教程,把埋点的代码嵌入到项目即可。
附赠
图 (1)
图 (2)
图 (3)
总结个人觉得,前端的工作都是集中在项目前期,后面的话主要是一些维护工作,比如公司之前开发了一个支持富文本内容的文章发布平台,然后运营部门就可以自己发一些引流的文章了,和开发关系不大。 另外,公司专门请了一个增长黑客(其实就是SEO优化工程师的角色),负责每周给公司写文章的同学提供关键词,分析网站访客数据,提交网站收录,寻找外链资源等。 该文章在 2024/10/14 10:29:06 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886