本文介绍 PostgreSQL 数据库的体系结构,包括实例结构(进程与内存)、存储结构(物理与逻辑)以及插件式存储引擎。
实例与数据库聚簇
PostgreSQL 使用典型的客户端/服务器(Client/Server)架构,客户端发送请求到服务端,服务端处理完成之后返回结果到客户端。下图显示了一个简化的 PostgreSQL 体系结构:
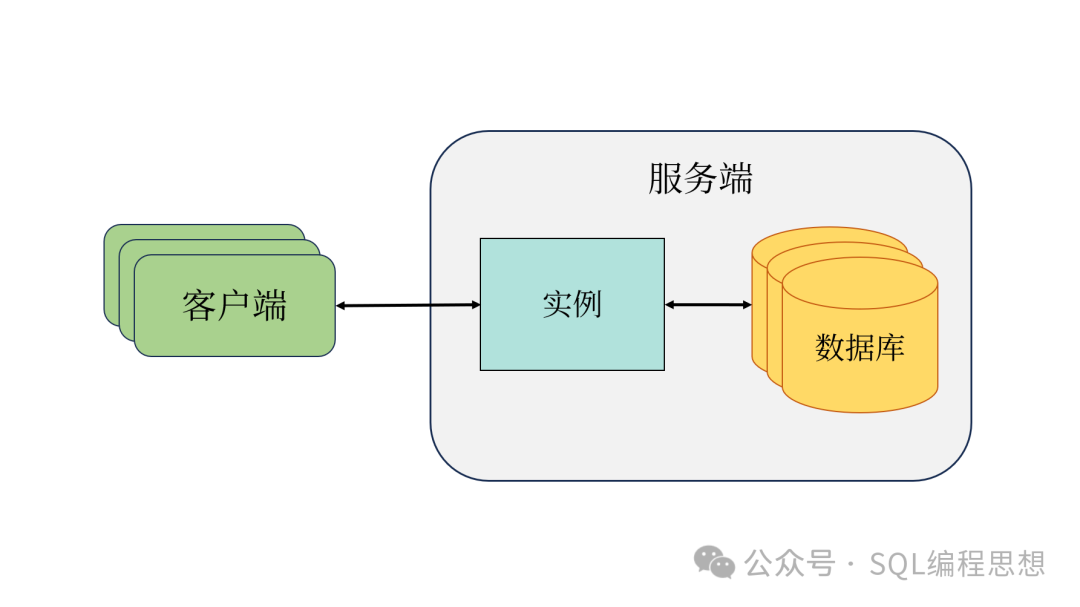
PostgreSQL 客户端可能是一个命令行工具、图形工具或者 Web 服务器,它们是数据库操作的请求者。
PostgreSQL 服务端由一个实例(Instance)以及一个数据库聚簇(Database Cluster)组成。
实例由一组后台进程和相关的内存组成,用于管理数据库。启动服务器进程时创建一个实例,关闭服务器进程时实例随之关闭。
数据库聚簇包含多个数据库,一个数据库由一组相关的对象组成,例如表、索引、视图、存储过程等。
提示:PostgreSQL 数据库聚簇代表了单个主机上单个实例管理的一组数据库,它不是由一组数据库服务器组成的集群。
客户端和服务端通常位于不同的主机中,它们之间通过 TCP/IP 网络协议进行连接和通信,默认端口为 5432。当客户端和服务端位于相同的主机时,也可以通过 Unix 域套接字进行通信。
实例结构
PostgreSQL 实例由一组进程和相关的内存组成,用于管理物理数据库。下图描述了实例的结构:

每当客户端进程请求连接数据库时,PostgreSQL 服务进程(postgres)负责监听连接请求并验证客户端信息。验证通过之后主服务进程会为每一个客户端连接创建一个新的后端进程,然后客户端进程和对应的后端进程(postgres)直接通信,后端进程代表客户端执行各种数据库操作并返回结果。
数据库进程
PostgreSQL?服务进程(server process)是其他进程的父进程,当我们启动 PostgreSQL 服务时首先会创建该进程,然后它再分配共享内存(shared memory)并启动各种后台进程。服务进程还负责监听客户端连接请求,默认监听端口为 5432。在早期版本中,PostgreSQL 服务进程也被称为 postmaster。
PostgreSQL?后端进程(backend process)用于代表客户端执行数据库操作,服务进程在验证客户端连接请求后为其创建新的后端进程,在客户端断开连接时终止对应的后端进程。
提示:PostgreSQL 使用类似 Oracle 中的专用服务器模式,每个客户端进程连接到一个专用的后端进程。后端进程在客户端会话期间不被任何其他客户端共享。每个新的会话都会分配一个专用的后端进程。
PostgreSQL 支持的最大客户端连接数由系统参数 max_connections 控制,默认值为 100。
PostgreSQL?后台进程(background processes)用于执行各种数据库管理操作,主要包括:
后台写进程(background writer),负责定期将共享缓冲池(shared buffer pool)中的脏页写入磁盘。
检查点进程(checkpointer),发生检查点时负责将检查点记录写入 WAL 段文件,同时刷新共享缓冲池中的脏页。
自动清理启动进程(autovacuum launcher),定期调用工作进程(autovacuum worker)完成清理工作。
WAL 写进程(wal writer),定期将 WAL 缓冲数据写入 WAL 段文件。
统计收集进程(stats collector),收集数据库系统运行的统计信息,PostgreSQL 15 版本优化删除。
归档进程(archiver),负责 WAL 段文件归档,也就是日志归档。
日志收集进程(logger),记录数据库错误日志。
除了以上进程之外,PostgreSQL 还会基于不同配置启动其他后台进程。例如,流复制相关的 walsender(发送 WAL 数据)以及 walreceiver(接收 WAL 数据)进程,用户自定义实现的后台工作进程(Background Worker Process)等。
后台写进程
后台写进程负责定期将共享缓冲池中的脏页写入磁盘,默认情况下每隔 200 毫秒(bgwriter_delay)刷新一次磁盘,每次最多刷新 100 个缓冲页(bgwriter_lru_maxpages)。这种刷新脏页的方式可以尽量减少对数据库性能的影响。
另外,PostgreSQL 9.1 版本之前,后台写进程还需要负责检查点过程。PostgreSQL 9.2 开始,单独的检查点进程开始负责这部分工作。
检查点进程
检查点进程负责检查点(Checkpoint)操作,也就是将检查点记录写入 WAL 段文件并且刷新共享缓冲池中的全部脏页。
以下情况都会触发检查点操作:
距离上一次检查点操作的时间间隔到达参数 checkpoint_timeout 的配置,默认为 300 秒。
PostgreSQL 9.4 以及更低版本,上一次检查点操作之后写入的 WAL 段文件数据到达参数 checkpoint_segments 的配置,默认值为 3。
PostgreSQL 9.5 以及更高版本,pg_wal(pg_xlog)目录中 WAL 段文件总大小超过参数 max_wal_size 的配置,默认值为 1 GB。
PostgreSQL 数据库服务以 smart(SIGTERM)或者 fast(SIGINT)模式关闭。
超级用户或者 pg_checkpoint 特权用户手动执行 CHECKPOINT 命令。
检查点机制可以将内存中的脏数据刷新到磁盘,并且生成一个一致性的数据库状态。系统崩溃后,执行数据库恢复时可以从最近的检查点开始,优化恢复性能。
自动清理启动进程
自动清理启动进程负责定期调用工作进程执行清理流程(VACUUM 以及 ANALYZE),默认情况下每隔 1 分钟(autovacuum_naptime)运行一次,每次最多调用 3 个(autovacuum_max_workers)工作进程。
WAL 写进程
WAL 写进程负责定期将 WAL 缓冲数据(XLOG)写入 WAL 段文件,这些文件位于 pg_wal 子目录中。
WAL 写进程默认 200 毫秒(wal_writer_delay)刷新一次缓冲,可以避免一次提交大量数据时的磁盘写入瓶颈。
统计收集进程
PostgreSQL 14 以及之前的版本中存在统计收集进程,负责收集系统运行时的统计信息,并且通过 pg_stat_activity 等动态视图提供数据。
PostgreSQL 15 版本开始使用累积统计系统,基于共享内存存储统计信息,优化了性能,同时删除了独立的统计收集进程。
归档进程
归档进程负责 WAL 段文件的连续归档,在发生 WAL 段切换时将其复制到归档区域。日志归档功能可以用于物理热备以及即时点恢复(PITR)。
如果想要启动 WAL 归档,需要将配置参数 wal_level 设置为 replica 或者更高级别,同时将配置参数 archive_mode 设置为 on,然后在 archive_command 参数中设置归档命令或者在 archive_library 参数中指定归档模块。
日志收集进程
日志收集进程负责将错误信息记录到错误日志文件,该进程由配置参数 logging_collector 控制,默认设置为 on。
内存结构
PostgreSQL 实例的内存结构可以分为以下两个大类:
共享内存区
PostgreSQL 实例启动时分配共享内存区,它是所有服务端进程共享的内存区,具体可以分为共享缓冲池(shared buffer pool)、WAL 缓冲(WAL buffer)、提交日志缓冲(CLOG)等。
共享缓冲池用于加载磁盘中的表和索引数据,并且在内存中进行操作,从而减少磁盘 I/O,提高性能。共享缓冲池的大小通过参数 shared_buffers 进行配置,默认值为 128 MB。
虽然对于 shared_buffers 没有具体的推荐值,但是可以针对具体的系统计算出一个大概的值。一般来说,对于专用的数据库服务器,shared_buffers 大概可以设置为系统内存的 25%。增加 shared_buffers 的值通常可以提高性能,例如,当整个数据库都可以被加载到缓存中时,可以明显减少磁盘的读取操作。由于 PostgreSQL 还依赖于操作系统的缓存,大于内存 40% 的 shared_buffers 并不会带来性能的提示,反而可能会下降。
另外,增加 shared_buffers 的值通常也需要相应地增加 max_wal_size 的值,以便延长检查点的时间间隔。
PostgreSQL 使用预写日志(WAL)确保数据的持久性;与 shared_buffers 作用类似,PostgreSQL 将 WAL 日志(XLOG)写入缓冲并且批量写入磁盘。
默认的 WAL 缓冲大小由 wal_buffers 参数进行设置,初始值为 4MB(shared_buffers 的 1/32)。WAL 缓冲区在每次事务提交时都会写入磁盘,因此过大的值并不会带来显着的性能提升。不过,对于大量并发的写入操作,适当增加该参数的值可以提高系统的性能。
CLOG 缓冲存储了每个事务的状态(IN_PROGRESS、COMMITTED、ABORTED 以及 SUB_COMMITTED),用户事务管理和并发控制。当 PostgreSQL 关闭服务或者执行检查点过程时,会将 CLOG 数据写入 pg_xact(pg_clog)子目录文件中;当 PostgreSQL 服务启动时,会从文件中加载初始 CLOG。
共享内存区还包括许多其他子区,例如用于实现各种访问控制机制(信号量、轻量级锁、共享锁、排他锁等)的内存,各种后台进程(checkpointer、autovacuum 等)使用的内存,事务处理(保存点、两阶段提交等)所需的内存。
本地内存区
本地内存区是为每个后端进程动态分配的独享内存区,用于执行查询处理、数据排序、哈希连接等操作,以及存储临时表和会话级别的数据。
本地内存区主要包括工作内存(work_mem)、维护工作内存(maintenance_work_mem)以及临时缓冲(temp_buffers)。
工作内存用于查询处理过程中的数据排序(ORDER BY、DISTINCT)以及表之间的连接(Hash Join、Sort Merge Join)等操作。工作内存由参数 work_mem 进行配置,默认为 4 MB。
如果设置了合适的 work_mem,大部分的排序操作都在内存中执行,而不需要使用磁盘存储临时结果。对于复杂的查询,可能会执行并发的排序或者哈希操作,每个操作都可以最多使用该参数设置的内存。另外,多个会话可能同时执行排序操作。因此,排序占用的总内存可能是 work_mem 的许多倍;work_mem 的值不能设置的过高,因为它可能导致内存使用瓶颈。
维护工作内存主要用于数据库维护操作,例如 VACUUM、CREATE INDEX 以及 ALTER TABLE ADD FOREIGN KEY 等操作。这些操作在执行时可能需要较大的内存空间来优化性能。
配置参数 maintenance_work_mem 指定了维护工作内存的大小,默认值为 64 MB。由于一个数据库会话同时只能执行一个维护操作,一般不会存在并发的维护操作;所以将该参数设置的比 work_mem 大很多也不会有问题,更大的维护内存还能够提高数据库清理和数据导入的性能。
临时缓冲用于存储临时表数据。每个会话都可以使用单独的临时缓冲来存储临时表的数据,以提高访问效率。
配置参数 temp_buffers 用于设置临时缓冲的大小,默认为 8MB。
存储结构
一个 PostgreSQL 实例管理一个数据库聚簇,它可以包含多个数据库。这里的聚簇不是多台服务器组成的集群。
物理存储
一个数据库聚簇通常对应操作系统中的一个目录,也就是根目录(PGDATA)。使用 SHOW 命令查看如下:
SHOW data_directory;
data_directory ? ? ? ? ? ? ? ? ? ? |
-----------------------------------+
D:/Program Files/PostgreSQL/17/data|
根目录包含多个子目录和文件:
PS D:\Program Files\PostgreSQL\17\data> ls
Mode ? ? ? ? ? ? ? ? LastWriteTime ? ? ? ? Length Name
---- ? ? ? ? ? ? ? ? ------------- ? ? ? ? ------ ----
d----- ? ? ? ? 2024/6/17 ? ? 10:44 ? ? ? ? ? ? ? ?base
d----- ? ? ? ? 2024/7/11 ? ? 14:35 ? ? ? ? ? ? ? ?global
d----- ? ? ? ? 2024/7/22 ? ? 17:08 ? ? ? ? ? ? ? ?log
d----- ? ? ? ? 2024/6/17 ? ? 10:44 ? ? ? ? ? ? ? ?pg_commit_ts
d----- ? ? ? ? 2024/6/17 ? ? 10:44 ? ? ? ? ? ? ? ?pg_dynshmem
d----- ? ? ? ? 2024/7/11 ? ? 14:39 ? ? ? ? ? ? ? ?pg_logical
d----- ? ? ? ? 2024/6/17 ? ? 10:44 ? ? ? ? ? ? ? ?pg_multixact
d----- ? ? ? ? 2024/6/17 ? ? 10:44 ? ? ? ? ? ? ? ?pg_notify
d----- ? ? ? ? 2024/6/17 ? ? 10:44 ? ? ? ? ? ? ? ?pg_replslot
d----- ? ? ? ? 2024/6/17 ? ? 10:44 ? ? ? ? ? ? ? ?pg_serial
d----- ? ? ? ? 2024/6/17 ? ? 10:44 ? ? ? ? ? ? ? ?pg_snapshots
d----- ? ? ? ? 2024/7/11 ? ? 14:34 ? ? ? ? ? ? ? ?pg_stat
d----- ? ? ? ? 2024/6/17 ? ? 10:44 ? ? ? ? ? ? ? ?pg_stat_tmp
d----- ? ? ? ? 2024/6/17 ? ? 10:44 ? ? ? ? ? ? ? ?pg_subtrans
d----- ? ? ? ? 2024/6/17 ? ? 10:44 ? ? ? ? ? ? ? ?pg_tblspc
d----- ? ? ? ? 2024/6/17 ? ? 10:44 ? ? ? ? ? ? ? ?pg_twophase
d----- ? ? ? ? 2024/6/17 ? ? 10:44 ? ? ? ? ? ? ? ?pg_wal
d----- ? ? ? ? 2024/6/17 ? ? 10:44 ? ? ? ? ? ? ? ?pg_xact
-a---- ? ? ? ? 2024/7/23 ? ? 17:16 ? ? ? ? ? ? 45 current_logfiles
-a---- ? ? ? ? 2024/6/17 ? ? 10:44 ? ? ? ? ? 5639 pg_hba.conf
-a---- ? ? ? ? 2024/6/17 ? ? 10:44 ? ? ? ? ? 2712 pg_ident.conf
-a---- ? ? ? ? 2024/6/17 ? ? 10:44 ? ? ? ? ? ? ?3 PG_VERSION
-a---- ? ? ? ? 2024/6/17 ? ? 10:44 ? ? ? ? ? ? 90 postgresql.auto.conf
-a---- ? ? ? ? 2024/6/17 ? ? 10:44 ? ? ? ? ?31602 postgresql.conf
-a---- ? ? ? ? 2024/7/11 ? ? 14:34 ? ? ? ? ? ? 91 postmaster.opts
-a---- ? ? ? ? 2024/7/11 ? ? 14:34 ? ? ? ? ? ? 70 postmaster.pid
下表列出了这些目录和文件的描述。
| 项目 | 类型 | 描述 |
|---|
| base | 目录 | 包含多个子目录,每个目录对应一个数据库。 |
| global | 目录 | 存储全局(聚簇)级别的数据表,例如 pg_database 等。控制文件也存储在这个目录中。 |
| log | 目录 | 存储服务器日志信息。 |
| pg_commit_ts | 目录 | 保存事务提交时间戳数据。 |
| pg_dynshmem | 目录 | 存储动态共享内存子系统使用的文件。 |
| pg_logical | 目录 | 存储逻辑解码状态数据。 |
| pg_multixact | 目录 | 存储用于共享行锁的多事务(multitransaction)状态数据。 |
| pg_notify | 目录 | 存储 LISTEN/NOTIFY(消息通知机制)状态数据。 |
| pg_replslot | 目录 | 存储复制槽数据。 |
| pg_serial | 目录 | 存储已提交的串行化事务信息。 |
| pg_snapshots | 目录 | 存储导出的快照。 |
| pg_stat | 目录 | 存储统计子系统使用的持久化文件。 |
| pg_stat_tmp | 目录 | 存储统计子系统使用的临时文件。 |
| pg_subtrans | 目录 | 存储子事务状态数据。 |
| pg_tblspc | 目录 | 存储表空间目录的符号链接。 |
| pg_twophase | 目录 | 存储预备事务(两阶段提交)的状态文件。 |
| pg_wal | 目录 | 存储预写式日志(WAL)文件。 |
| pg_xact | 目录 | 存储事务提交状态数据。 |
| current_logfiles | 文件 | 记录当前写入的服务器日志文件。 |
| pg_hba.conf | 文件 | 客户端认证配置文件。 |
| pg_ident.conf | 文件 | 用户名映射文件。 |
| PG_VERSION | 文件 | 记录 PostgreSQL 主版本号。 |
| postgresql.auto.conf | 文件 | 存储使用 ALTER SYSTEM 命令设置的参数信息。 |
| postgresql.conf | 文件 | 主配置参数文件。 |
| postmaster.opts | 文件 | 记录服务器上次启动时使用的命令行选项。 |
| postmaster.pid | 文件 | 记录主服务进程 ID,数据库聚簇根目录,主服务进程启动时间戳,服务端口、Unix 域套接字目录(可空),第一个有效的监听地址以及共享内存段 ID 等信息。该文件在服务启动时创建,服务停止时删除。 |
其中,base 子目录存储了每个数据库的数据文件和索引文件等内容:
PS D:\Program Files\PostgreSQL\17\data\base> ls
Mode ? ? ? ? ? ? ? ? LastWriteTime ? ? ? ? Length Name
---- ? ? ? ? ? ? ? ? ------------- ? ? ? ? ------ ----
d----- ? ? ? ? 2024/6/20 ? ? ?9:09 ? ? ? ? ? ? ? ?1
d----- ? ? ? ? 2024/6/17 ? ? 10:44 ? ? ? ? ? ? ? ?4
d----- ? ? ? ? 2024/7/11 ? ? 14:35 ? ? ? ? ? ? ? ?5
每个数字子目录对应一个数据库的标识符(OID),使用 SQL 查询数据库信息如下:
select oid, datname
from pg_database;
oid|datname ?|
---+---------+
?5|postgres |
?1|template1|
?4|template0|
数据库中的对象存储在各自的子目录中,pg_relation_filepath 函数可以用于查询对象的文件路径(相对于根目录):
SELECT pg_relation_filepath('public.animal');
pg_relation_filepath|
--------------------+
base/5/73734 ? ? ? ?|
animal 是数据库 postgres 中的一个表,它的 OID 为 73734,数据文件为根目录下的 base/5/73734。
表空间
在 PostgreSQL 中,表空间(tablespace)表示数据文件的存放目录,这些数据文件代表了数据库的对象,例如表或索引。创建数据库对象时,只需要指定存储对象的表空间的名称(或者使用默认值),而不需要指定磁盘上的物理路径。当我们访问表时,系统通过它所在的表空间定位到对应数据文件所在的位置。

PostgreSQL 中的表空间与其他数据库系统不太一样,它更偏向于一个物理上的概念。
表空间的引入为 PostgreSQL 的管理带来了以下好处:
PostgreSQL 在集群初始化时将默认创建了两个表空间:
创建表和索引时的默认表空间使用参数 default_tablespace 进行配置。使用 CREATE 命令指定表空间的语法如下:
CREATE TABLE ...
TABLESPACE ts_name;
逻辑存储
一个数据库聚簇包含多个数据库。数据库由一组相关的对象组成,例如表、索引、视图、存储过程等。数据库中的对象使用模式(Schema)进行逻辑组织。准确地说,一个数据库由多个模式组成,模式由许多对象组成。
PostgreSQL 的逻辑存储结构如下图所示:
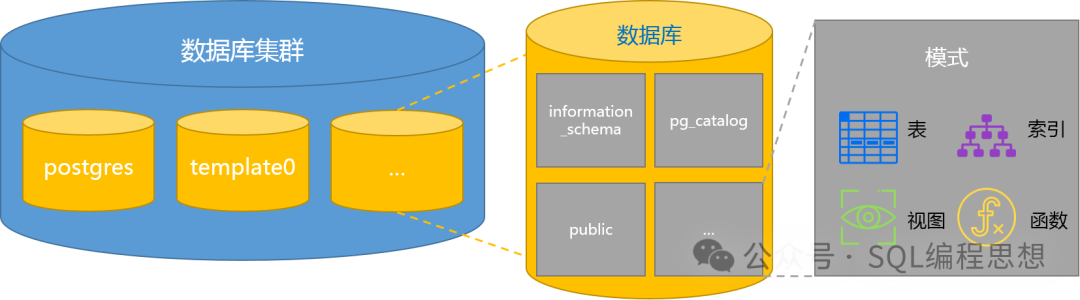
多个数据库之间是物理隔离的,每个数据库在 PostgreSQL 中都对应一个独立的目录,其中包含该数据库的所有数据文件和元数据。客户端连接服务器时需要指定数据库名称,连接到一个数据库的客户端无法查询另一个数据库中的数据,除非使用外部数据封装器(FDW)。
一个数据库中的多个模式之间是逻辑隔离的,不同模式中可以存在同名的对象,例如 schema1 和 schema2 中都可以存在名为 test 的数据表。PostgreSQL 权限管理系统控制模式对象的访问,访问对象时可以包含模式名称,例如 schema1.test。
每个数据库对象都有一个唯一的标识符(OID),它是一个无符号的四字节整数。这些标识符用于在系统表中唯一标识不同的数据库对象。例如,数据库的 OID 存储在 pg_database 表中,模式的 OID 存储在 pg_namespace 表中,关系(表、索引、序列、视图、复合类型等)的 OID 存储在 pg_class 表中。通过这些标识符,PostgreSQL 能够在内部有效地管理和引用各种数据库对象。
存储引擎
PostgreSQL 12 开始支持插件式表访问方法(Table Access Method),基于这个接口可以实现不同的数据存储引擎,针对特定的工作负载定制数据的存储和检索方式,从而提高系统的整体性能。
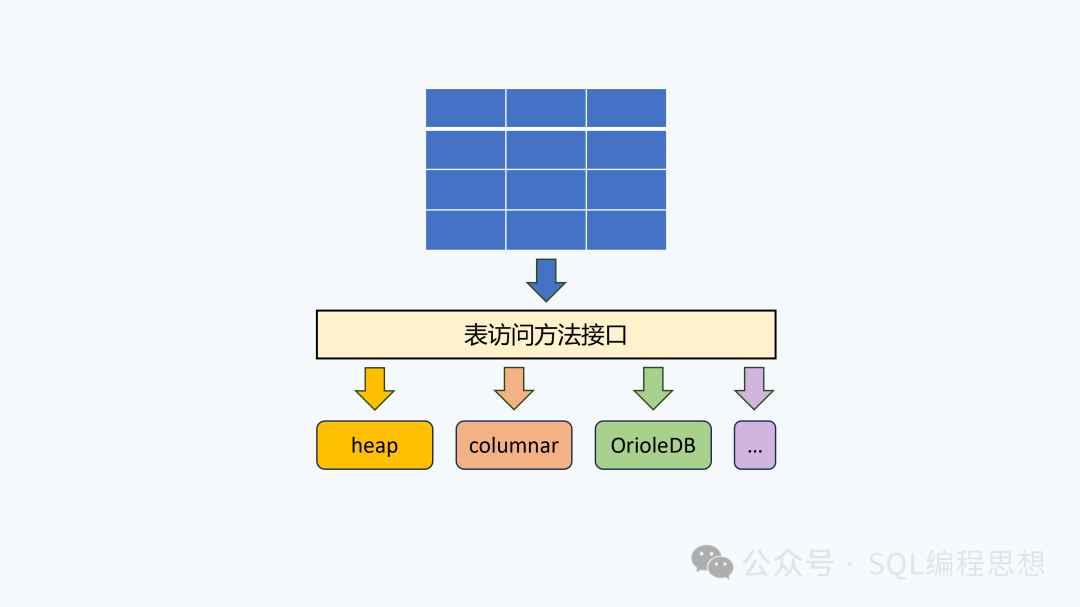
默认的数据存储引擎为 heap(堆表),使用参数 default_table_access_method 进行设置:
SHOW default_table_access_method;
default_table_access_method|
---------------------------+
heap ? ? ? ? ? ? ? ? ? ? ? |
用户创建表或者物化视图时可以指定存储引擎,语法如下:
CREATE TABLE ...
USING method;
除了默认的 heap 之外,已知正在开发的存储引擎包括 columnar 和 OrioleDB 等。
PostgreSQL 也支持插件式索引访问方法(Index Access Method),并且基于这个接口实现了 B-Tree、Hash、GiST、GIN 等不同的索引类型,同时用户也可以扩展自定义的索引类型,从而优化不同场景下的查询性能。
该文章在 2024/7/30 18:46:28 编辑过






 400 186 1886
400 186 1886


